Outil de prédiction avec Keras et Tensorflow
Cela fait longtemps que je souhaite utiliser un réseau de neurones pour faire de la prédiction de signaux. Le Kit de Trading en Python est l'occasion de mettre en oeuvre ces technologies.
 |
| Image d'un réseau de neurones |
J'avais mis au point un premier algorithme avec la mise en oeuvre de Keras et TensorFlow pour entraîner un réseau de neurones et faire de la prédiction et un jour il n'y a pas si longtemps, j'ai eu l'idée de demander à ChatGpt comment améliorer cet algorithme.
Voici la réponse de ChatGpt :
Pour améliorer votre algorithme de prédiction des cours de la bourse, vous pouvez envisager plusieurs approches à la fois sur le plan de la pré-traitement des données, la modélisation et l'évaluation des performances.
Voici quelques suggestions détaillées :
1. Pré-traitement des données
Diversification des caractéristiques
Ajoutez plus de caractéristiques : Outre les prix de clôture, incluez d'autres caractéristiques comme les volumes de transaction, les prix d'ouverture, de plus haut et de plus bas, les indicateurs techniques (Moyennes mobiles, RSI, MACD, etc.).
Lagged features : Créez des caractéristiques décalées dans le temps (par exemple, les prix de clôture des jours précédents) pour capturer les dépendances temporelles.
Normalisation des données
Revisitez la normalisation : Assurez-vous que la normalisation est effectuée de manière cohérente pour les ensembles de formation, validation et test. Évitez la fuite de données entre ces ensembles.
2. Modélisation
Architecture du modèle
Augmentez les unités LSTM : Expérimentez avec un nombre plus élevé d'unités LSTM pour capturer des relations plus complexes.
Ajoutez plus de couches : Essayez d'ajouter plus de couches LSTM et des couches de récurrence bidirectionnelle (Bidirectional LSTM) pour améliorer la capacité de modélisation des dépendances temporelles.
Régularisation
Régularisation : Utilisez d'autres techniques de régularisation comme le L2 regularization pour éviter le surapprentissage.
3. Entraînement et validation
Validation croisée
Validation croisée : Utilisez la validation croisée (par exemple, K-Fold) pour évaluer la performance de votre modèle de manière plus robuste.
Early Stopping et ajustement des hyperparamètres
Early Stopping : Utilisez l'early stopping pour arrêter l'entraînement lorsque la performance sur le jeu de validation ne s'améliore plus.
Grid Search/Random Search : Utilisez des techniques de recherche d'hyperparamètres pour trouver les meilleures configurations (nombre de couches, unités LSTM, taux de dropout, etc.).
4. Évaluation des performances
Mesures de performance
Ajoutez d'autres mesures : Utilisez d'autres métriques comme le MAE (Mean Absolute Error) et le MAPE (Mean Absolute Percentage Error) pour une évaluation plus complète.
5. Prédiction à long terme
Prédiction récursive
Prédictions récursives : Lorsque vous faites des prédictions à long terme, utilisez les prédictions précédentes comme nouvelles entrées (comme vous l'avez déjà fait) mais assurez-vous que l'incertitude de la prédiction est bien gérée.
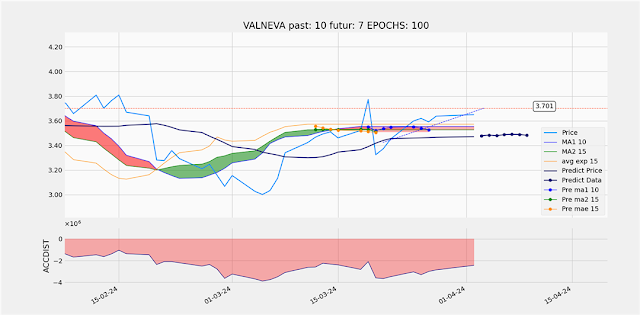
Résultats
Voici donc un champ de travail ouvert et j'ai commencé à utiliser ces prescriptions. Voici rapidement sur trois graphiques les résultats de l'amélioration de mon algorithme.
 |
| Résultat obtenus avec la première version |
Première amélioration l'ajout de couches de récurrence bidirectionnelles
 |
| Ajout de couches de récurrence bidirectionnelles |
Et puis j'ai augmenté les unités LSTM :
 |
| Augmentation des couches LSTM |
Si vous avez la possibilité avec votre navigateur de comparer ces trois graphiques vous pourrez rapidement constater que les améliorations de l'algorithme de prédictions sont significatives.
Si vous souhaitez bénéficier de ces travaux et de bien plus encore, je vous propose de vous rendre page suivante :
Trading et Data Analyses en Langage Python
Notes sur les améliorations futures
Comment régler le paramètre Dropout ?
Le taux de Dropout est un hyperparamètre qui indique la fraction des unités à désactiver. Voici quelques points à considérer pour choisir le bon taux de Dropout :
Dropout couramment utilisés se situent entre 0.2 et 0.5. Un taux de 0.2 signifie que 20 % des unités sont désactivées à chaque itération d'entraînement.
Si le taux de Dropout est trop faible (par exemple, inférieur à 0.2), la régularisation peut être insuffisante, ce qui peut entraîner un surapprentissage.
Si le taux de Dropout est trop élevé (par exemple, supérieur à 0.5), le modèle peut sous-apprendre, car trop d'unités sont désactivées, ce qui réduit sa capacité d'apprentissage.
Documentation Keras
Abonnez-vous à la plateforme TradingInPython
Pour profiter de cette technologie intégrée dans le plateforme TradingInPython :







Commentaires
Enregistrer un commentaire
Merci pour votre commentaire.
S'il n'apparaît pas tout de suite c'est qu'il est en attente de modération.
Merci de votre compréhension.